Workload Resources
- Jun 22, 2025
- 9 min read
In Kubernetes, Workload Resources are the objects that we use to deploy and manage our containerised applications. Think of them as blueprints that tell Kubernetes how our application (which is called as, workload) should run, for example, how many copies it should have, how to update it, and how to recover if something goes wrong.
Now as we know, that our application (workload) run inside a pod, however, maintaining each pod separately is tedious and error prone, and for that purpose, we usually don't manage each pod directly and instead, we use workload resources that manage a set of pods on our behalf.
Behind the scenes, each workload resource is linked to a controller, which continuously watches and ensures that the actual state (running pods) matches what we defined. If a pod crashes or is deleted, the controller recreates it to maintain the correct number and configuration.
There are different workload resource types, which are built-in to support different application patterns, stateless, stateful, scheduled, or node-bound workloads. And now we will actually dive into types of workload resources exists in Kubernetes.
Deployment and ReplicaSet
Deployment (object, Deployment) declaratively manages stateless applications. It defines a desired state (including, number of replicas (replication of pods), pod spec and update strategy) and ensures the actual state matches it.
Deployment is backed internally by another object called a ReplicaSet, which in turn manages the actual pods. Each of these object, Deployment and ReplicaSet, has its own controller in the control plane, Deployment controller and ReplicaSet controller respectively.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80When we create a Deployment workload resource (by using Deployment manifest file), Kubernetes doesn't directly create pods. Instead, deployment controller which is watching this Deployment. Creates or updates a ReplicaSet object that matches the pod template in the deployment’s spec. And now the replicaSet controller which watches this ReplicaSet and creates the actual pods. If a pod crashes, the ReplicaSet recreates it. If we update the Deployment (say, change the image), the deployment controller creates a new ReplicaSet with the new template and gradually shifts pods over (rolling update), managing both old and new ReplicaSets during the transition.
A Deployment doesn’t manage pods directly ⭐. Instead, it manages a ReplicaSet, which in turn manages the actual pods. This separation exists because ReplicaSet is a lower-level primitive responsible only for maintaining a specific number of identical pods. The Deployment adds higher-level features like, rolling updates, rollbacks, version history and declarative updates. For example, when we want to update our application to a new version (say from version 1 to version 2), we don’t want downtime or manual restarts. In this case, Deployment helps us, by creating new ReplicaSets behind the scenes and then gradually switch traffic from the old version to the new one without downtime (rolling updates) and roll back to the old version if issue in new version. So using these two objects, we achieves separation of concerns. StatefulSet (discussed later) doesn’t use an intermediate like ReplicaSet, because it directly manages individual pods with persistent identity and stable storage.
Say we have the nginx-deployment.yaml Deployment manifest file (attached above), and when we apply this using,
kubectl apply -f nginx-deployment.yamldeployment controller notices the new Deployment and creates a corresponding ReplicaSet, say nginx-deployment-7bcd9d4c6d, with the same pod template. We can even verify this by inspecting the created ReplicaSet using,
kubectl get rs
kubectl get rs <replica-set-name> -o yaml
The output of this created ReplicaSet that we got from Kubernetes is this,
apiVersion: apps/v1
kind: ReplicaSet
metadata:
annotations:
deployment.kubernetes.io/desired-replicas: "2"
deployment.kubernetes.io/max-replicas: "3"
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2025-05-17T16:28:10Z"
generation: 1
labels:
app: nginx
pod-template-hash: 764dd87c46
name: nginx-deployment-764dd87c46
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: Deployment
name: nginx-deployment
uid: 6b850aa5-7359-4b12-8432-55200d1ec4ef
resourceVersion: "65129"
uid: ceaebdaa-6176-4a7a-9fc3-83d7891c074e
spec:
replicas: 2
selector:
matchLabels:
app: nginx
pod-template-hash: 764dd87c46
template:
metadata:
creationTimestamp: null
labels:
app: nginx
pod-template-hash: 764dd87c46
spec:
containers:
- image: nginx:1.21
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 2
fullyLabeledReplicas: 2
observedGeneration: 1
readyReplicas: 2
replicas: 2
The ownerReferences field ties the ReplicaSet back to the Deployment, so if the Deployment is deleted, the ReplicaSet can be garbage-collected too. Also note that the pod template in the ReplicaSet is copied directly from the Deployment. So the ReplicaSet manages the pods and keeps 2 of them running. If one crashes, the ReplicaSet (not Deployment) recreates it. If we update the Deployment (say, change image to nginx:1.22), it will create a new ReplicaSet with a new hash name and start a rolling update.
StatefulSet
A StatefulSet is a workload resource like Deployment, but it’s designed for managing stateful applications, applications where each pod must have,
A stable network identity, which refers to the stable hostname (DNS) and network address that a pod can be reached by, and in StatefulSet, each pod gets a persistent hostname, like mysql-0, mysql-1, and keeps it across restarts.
persistent volume (stable storage), where each pod is assigned a persistent volume claim (PVC) that’s bound to its identity. Even if a pod shutdown and restarts on another node, it gets its original volume.
ordered lifecycle management, i.e. a known startup/shutdown order. For example, pods are created one at a time and on deletion or update, they’re stopped in reverse order.
For example, Databases (like MongoDB, Kafka, PostgreSQL) can use StatefulSet, because, in case of databases, we can’t just replace pods like in a deployment because each one stores unique state or data.
Just like Deployment or ReplicaSet, StatefulSet is an object (StatefulSet) and managed by its own controller, the StatefulSet controller, part of the control plane.
In a Deployment, pod’s identity are random (nginx-5f97d4bdcc-abcde), and when a pod restarts, it may get a new name and IP, so clients can’t rely on a fixed address. In a StatefulSet, each pod gets a predictable, stable name and DNS like, web-0.nginx.default.svc.cluster.local and web-1.nginx.default.svc.cluster.local This DNS name stays the same even if the pod restarts. It allows components like database nodes to consistently talk to each other at known addresses.
Unlike Deployment, StatefulSets do not create ReplicaSets underneath. The StatefulSet controller directly manages the pods, i.e. it handles each pod individually by name (<name>-0, <name>-1, and so on), not as interchangeable replicas. This is because StatefulSet needs precise control over pod’s identity, which ReplicaSet is not designed for.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
replicas: 2
selector:
matchLabels:
app: nginx
serviceName: "nginx" # headless service for DNS
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
This StatefulSet will create, two pods (named web-0 and web-1), each with a unique persistent volume claim (www-web-0 and www-web-1) and a stable DNS (web-0.nginx.default.svc.cluster.local and web-1.nginx.default.svc.cluster.local).
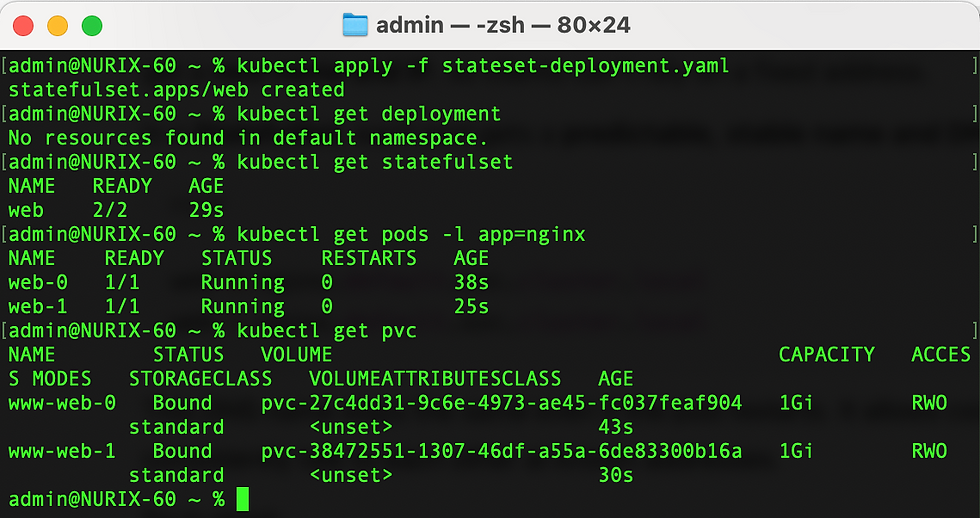
Now we will delete one of the pod (say web-0), and then check the pods by using kubectl get pods,

Here, we can see that a new pod with same identity is created. And we can also confirm that this new pod got the same volume by checking this new pod object’s manifest file.

DaemonSet
A DaemonSet is an object (DaemonSet) used to ensure that a specific pod runs on every node (or a subset of nodes) in a cluster. It’s ideal for running background system services, such as, log collectors, monitoring agents, security tools and network plugins. It is managed by the DaemonSet controller.
⭐ We need a DaemonSet because certain services, like log collectors, monitoring agents, or network plugins, must run on every node to function correctly. Also they aren't application-level workloads but rather infrastructure-level agents. These agents collect data, enforce policies, or enable networking, and they need to operate alongside all application pods across the cluster. The DaemonSet coexist with other workload types like ReplicaSet in the same namespace or cluster to serve different roles. For example, while a Deployment or ReplicaSet might run our web application with multiple replicas, a DaemonSet ensures that each node has a logging or monitoring pod running locally, collecting node-level data or enabling cluster-wide behaviour. This separation of concerns ensures clean management, where, DaemonSets handle node-wide services, while Deployments or StatefulSets handle application logic.
DaemonSet, like StatefulSet, needs direct control over pods because its core function, is to ensure exactly one pod per node and this requires fine-grained scheduling decisions that a ReplicaSet can’t handle.
ReplicaSets operate on maintaining a desired number of pods across the cluster, but they have no concept of which nodes those pods run on or whether every node is covered. DaemonSet, on the other hand, must track nodes individually and place a pod on each one (or a filtered set of nodes). It also need to react to node’s lifecycle events, for example, when a new node is added, it must immediately schedule a new pod there, and if a node goes down, its associated pod must be removed. This level of node-specific orchestration requires a dedicated controller with logic tailored to node-to-pod mapping, not just replica count, which is why it bypasses ReplicaSet and manages pods directly.
A DaemonSet, does not use a pod count (replicas), instead, creates one pod per eligible node and react to node’s lifecycle events.
When we define a DaemonSet, DaemonSet controller on noticing this new DaemonSet object, schedules one instance of its pod on every node that matches the selector. There is no rolling updates by default, and updating a DaemonSet object, typically replaces pods one-by-one unless specified otherwise. We can optionally limit which nodes run the DaemonSet pods using, node selectors, node affinity, and taints and tolerations.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-logger
spec:
selector:
matchLabels:
name: logger
template:
metadata:
labels:
name: logger
spec:
containers:
- name: logger
image: busybox
command: ["/bin/sh", "-c", "while true; do echo Node: $(hostname); sleep 60; done"]
After applying, we will see that there is one pod per node. If we add a new node, the DaemonSet controller will automatically schedule the same pod on it.
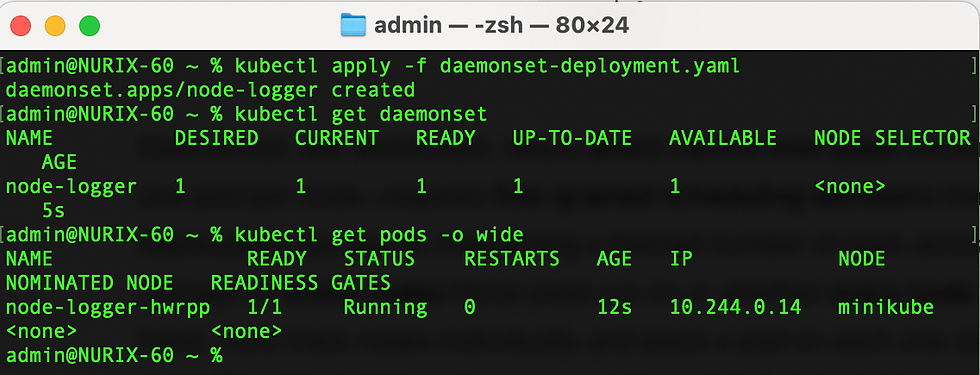
Job
A Job is a object (Job) designed to run a task to completion, rather than continuously like Deployments, StatefulSet or DaemonSets. It ensures that a specific number of pods successfully terminate after doing their work. It’s ideal for short-lived or batch tasks.
We define a Job with a pod template, just like other workload resources, but instead of keeping the pod running, Job controller watches for the pod(s) to succeed, i.e., exit with 0. Once the desired number of completions is reached, the Job is marked Completed, and its pods won't restart unless specified. For example, we are creating a Job that runs a pod that prints “data flushed” and sleeps for 10 seconds before and after printing.
apiVersion: batch/v1
kind: Job
metadata:
name: data-flush-job
spec:
template:
spec:
containers:
- name: data-flush
image: busybox
command: ["sh", "-c", "sleep 10; echo data flushed; sleep 10"]
restartPolicy: Never
backoffLimit: 4
Here, we can see that our Job was successfully completed and the print statement worked successfully.

CronJob
A CronJob is a higher-level controller built on top of Job, designed to run tasks on a recurring schedule. Instead of running once like a Job, a CronJob defines when and how often a Job should be created and executed. At each scheduled time, the CronJob controller creates a new Job object, and that Job runs to completion.
Internally, the CronJob controller parses the cron expression (schedule:), and on each tick, it spawns a new Job, which creates pods as needed. Kubernetes tracks the status of each Job and cleans them up depending on our successfulJobsHistoryLimit and failedJobsHistoryLimit.
apiVersion: batch/v1
kind: CronJob
metadata:
name: notification-cron
spec:
schedule: "*/1 * * * *" # every minute
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["sh", "-c", "date; echo notified"]
restartPolicy: OnFailure
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1

We will see a new Job every minute, and each job will spawn a pod, run the command, and exit.
Conclusion
For all of these workload resources we discussed, their dedicated controller uses the PodTemplate inside the workload resources object to make actual pods. The PodTemplate is part of the desired state of whatever workload resource we used to run our application.
Modifying the PodTemplate or switching to a new PodTemplate has no direct effect on the pods that already exist. If we change the PodTemplate for a workload resource, that resource needs to create replacement pods that use the updated template instead of updating or patching the existing pods.
For example, the StatefulSet controller ensures that the running pods match the current PodTemplate for each StatefulSet object. If we edit the StatefulSet to change its PodTemplate, the StatefulSet starts to create new pods based on the updated template. Eventually, all of the old pods are replaced with new pods, and the update is complete.
Each workload resource implements its own rules for handling changes to the PodTemplate. If you want to read more about StatefulSet specifically, you can read Update strategy.